Redis is great for storing certain types of data that do not do well in a relational database. It is great for storing caches and statistics too. However, the storage capacity of redis is capped by RAM size, so care is required when storing large amounts of data in it.
I will show you a trick to reduce memory usage and improve the speed of the redis list type for storing series-type data (e.g. time series).
Redis packs small lists of ints, reducing their memory usage by 10-40%.
The exact list size threshold at which redis stops compressing is defined by the list-max-ziplist-entries setting and defaults to 512.
Here is the trick: we will transparently partition a list into many small lists of list-max-ziplist-entries size.
By storing lists under the threshold, we take advantage of redis' ability to pack them.
Here is a memory usage benchmark with random int values between 0 and 10:
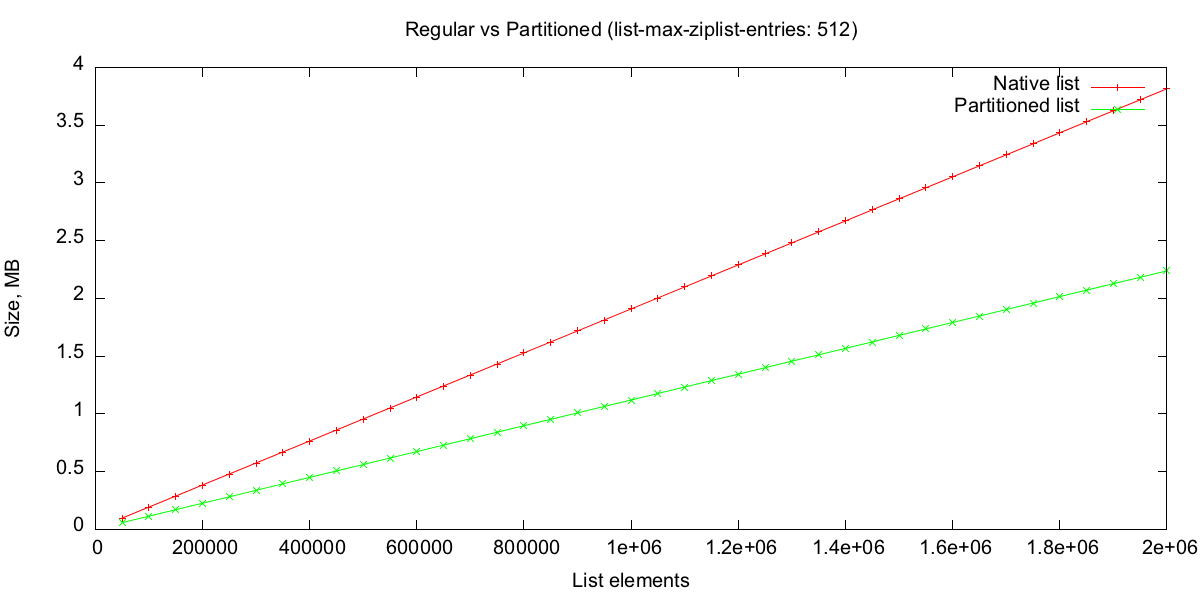
To benchmark access speed let's try some random accesses on a large list:
bm_speed: 3,000,000 keys, 100 random range reads
user system total real
regular 0.380000 0.040000 0.420000 ( 0.686875)
partitioned 0.390000 0.060000 0.450000 ( 0.482544)
Even despite Ruby overhead we still have both wall-clock time and memory savings.
A regular redis list is a linked list, so getting ranges out of it is slow.
However, when we use this technique the list is partitioned, and it only takes O(1) to get to the correct partition.
As you increase list-max-ziplist-entries, memory savings increase and range queries get slower.
I published a Ruby implementation of this approach for int and time series.
Are you doing something similar? I am curious to hear other approaches.
Thanks @ddtrejo for your edits and suggestions!
Notes
- Packing efficiency depends on the data. Benchmark with your real data.
- You can implement a similar trick for hashes and sets, redis will compress them based on the respective
-ziplist-entriesvalues. - Tested on redis 2.6.14, installed via homebrew on OS X 10.8.3.
See also
- Discussion on Hacker News.
- Instagram dev blog post on storing key-value pairs using partitioned hashes.
- Redis in Action book by @dr_josiah.